转帖来源http://www.sohu.com/a/260229041_807475
这个对DMA双缓冲总结得很好,分享给大家
目前STM32家族中有些系列支持DMA的双缓冲模式,比如STM32F2/STM32F4/STM32F7等系列。尤其随着人们对STM32F4/F7系列应用不断拓宽和加深,在设计中运用到DMA双缓冲的场合也越来越多。STM32芯片中的DMA又可分为两大类,一类是通用DMA,一类是专用DMA,比如用于USB,TFT LCD,ETHERNET等外设应用上的DMA。这里要谈的是基于通用DMA的话题,不妨以STM32F4系列芯片为例。 关于STM32F4的DMA双缓冲传输在STM32F4系列的参考手册里做了简单描述。因为它是基于介绍了单缓冲模式的DMA介绍之后接着介绍的,稍显言简意赅。 - 相比单缓冲的数据流,双缓冲多了一个DMA存储区和相应的存储指针;
- 如果使能DMA双缓冲,硬件会自动使能DMA的循环传输模式;
- 每一批数据传输结束,或者说每次传输事务结束时通过交换存储指针实现更换存储区的目的。
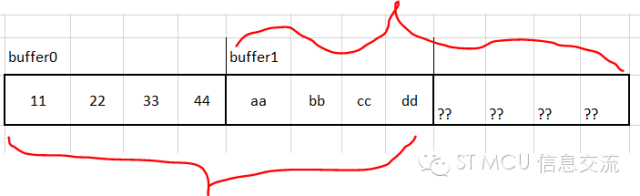
4.DMA双缓冲模式仅在外设与存储器间进行,不支持memoryto Memory间的传输。 基于DMA双缓冲模式的的特点,不难理解在应用中必须开辟两个存储区以及存放两个存储区首地址的存储寄存器,DMA_SxM0AR和DMA_SxM1AR。 DMA_SxM0AR:指向存储区0,单缓冲模式下默认使用该寄存器做存储区指针。 DMA_SxM1AR:指向存储区1,仅在DMA双缓冲模式下才能使用。 DMA正在访问的当前存储区由CT@DMA_SxCR位表示 CT = 0:DMA正在访问存储区0,CPU可以访问存储区1 CT = 1:DMA正在访问存储区1,CPU可以访问存储区0 使用DMA双缓冲传输,既可以减少CPU的负荷,又能最大程度地实现DMA数据传输和CPU数据处理互不打扰又互不耽搁,同时也给应用开发也带来方便。比如,假设你使用DMA单存储缓冲,有些情况下可能是等待DMA搬完了数据,CPU才过来处理;有些情况下可能是DMA一边传输,CPU也一边来访问,这时往往会使用到环形存放和读取,代码实现起来稍显繁琐也容易出纰漏。如果改为DMA双缓冲模式,应用上实现起来也就简洁很多。再加上DMA双缓冲模式的循环特性,使用它对存储区的空间容量要求也会大大降低。尤其在大批量数据传送时,你只需开辟两个合适大小的存储区,能满足DMA在切换存储区时的当前新存储区空出来就好,并不一定要开辟多大多深的存储空间。有过这方面应用经验的工程师可能就有体会,单纯一味地加大双缓冲区的深度并不明显改善数据传输状况。 关于这点不妨打个比方,某茶馆有俩芳名分别为CPU和DMA的伺茶MM,,每人手里有个同样茶壶。DMA负责把她手里的茶壶装满茶水就好,CPU就负责用从DMA手里接过装满茶水的壶给客人倒茶,倒完了用空壶与DMA交换装满茶水的壶继续工作。显然,只要保证CPU妹妹茶壶里总有茶水,至于那两个茶壶选多大容积并不是很重要。倒是那个茶壶进出口径对整个事情的效率有影响。 关于DMA双缓冲话题,我们也不妨看看一个具体的案例加深下印象。案例来自网络,为了尽量压缩篇幅,我省却了部分配置代码,留下需要交流的关键语句。 &&&&&&&&&&&&&&&&& F407 DMA的double Buffer mode上卡了好久了!大家看看配置哪里出问题了? uint8_tBuffer0[] = {0x11,0x22,0x33,0x44}; //无符号的8位整型数 uint8_tBuffer1[] = {0xaa,0xbb,0xcc,0xdd}; //无符号的8位整型数 voidUSART3_DMA1_Configuration(void) { ...... DMA_InitStructure.DMA_PeripheralBaseAddr= USART3_DR_Addr; //外设首地 DMA_InitStructure.DMA_Memory0BaseAddr= (uint32_t)Buffer0; //内存区首地址(1) DMA_InitStructure.DMA_DIR= DMA_DIR_MemoryToPeripheral; //内存->外设 DMA_InitStructure.DMA_BufferSize= 8; //*****传输数据个数为8 *****(2) DMA_InitStructure.DMA_PeripheralInc= DMA_PeripheralInc_Disable; DMA_InitStructure.DMA_MemoryInc= DMA_MemoryInc_Enable; // DMA_InitStructure.DMA_PeripheralDataSize= DMA_PeripheralDataSize_Byte; DMA_InitStructure.DMA_MemoryDataSize= DMA_MemoryDataSize_Byte; DMA_InitStructure.DMA_Mode= DMA_Mode_Circular; //循环传输 …… DMA_DoubleBufferModeConfig(DMA1_Stream3,(uint32_t)Buffer1, DMA_Memory_1);//(3) DMA_DoubleBufferModeCmd(DMA1_Stream3,ENABLE);// (4) enable double buffle DMA_Init(DMA1_Stream3,&DMA_InitStructure); DMA_Cmd(DMA1_Stream3,ENABLE); //使能 DMA1_Stream3通道 DMA_ClearITPendingBit(DMA1_Stream3,DMA_IT_TCIF3); DMA_ITConfig(DMA1_Stream3,DMA_IT_TC, ENABLE); } &&&&&&&&&&&&&&&&& 发帖者述说,如果将蓝色语句(3)的DMA_Memory_1改成DMA_Memory_0的话,就能正常打印出 11 22 33 44 aa bb cc dd,如果换成DMA_Memory_1的话,现象就不对了!输出的结果却是aa bb cc dd 15 00 08 52。请问是怎么回事? 显然发帖者使用STM32F4系列芯片DMA的双缓冲功能,应该只是做做实验而已。他开辟了两个长度均为4字节的缓冲存储区BUFFER0和BUFFER1。从基于ST固件库函数代码配置角度看,双缓冲模式相比单缓冲模式,就是多了(3)(4)两句,其它都一样。这里我们特别留意下其中(1)(2)(3)句配置代码。 绿色语句(1)配置了存储区0指针指向的地址; 红色代码语句(2)处给出了DMA每轮的传输数据个数8; 蓝色代码语句(3)处配置存储区1的地址和选择第一个当前存储区; 整体上看,该配置都配置了。结合我们上面的原理介绍,可以看出红色代码语句(2)配置每轮DMA传输个数为8有点问题,传输的数据宽度为BYTE,两个缓冲区各自空间大小为4 BYTE。也就是说每传输4个BYTE数据就轮换存储区重开下一轮传输,每轮DMA传输的数据个数应该是4而不是8。 现在发帖者反馈的是调整语句(3)便会呈现不同的结果,当把第(3)句的当前存储区改为Memory0时就会呈现貌似正确的结果。那是为什么呢? 其实这个貌似正确的结果是种巧合的假象。巧合的是在定义BUFFER0和BUFFER1时,因为二者紧邻在一起定义,编译器刚好把二者安排在连续的8个字节存储单元。而发帖者又刚好将每轮DMA传输数据个数定义为8个缓冲单元,这意味着每传输8个缓冲单元数据才切换缓冲区。当从Memory0即BUFFER0开始传输时,连续的8个数据在第一轮就读了出来,也就是说这8个数据并未经过缓冲区的切换就读出来了。而当发帖者把第(3)句的第一次使用的当前存储区改为Memory1时就没那么幸运了。因为这次DMA从BUFFER1开始连续读取8个数据单元,读完BUFFER1内的4个单元后,后面的4个缓存单元就是些不确定的数据,自然一眼就看出结果不对了。 实际上,当把上面红色代码语句(2)处的DMA传输数据个数调整为4时就结果正常了,至于第(3)句的起始当前缓冲区的选择无关紧要。 有人在使用DMA双缓冲模式时,经常为这个传输个数纠结,尤其从单缓冲模式转为双缓冲模式时。其实,不管单缓冲还是双缓冲模式,对于整体需要传输的数据个数是不会增减的,只是双缓冲模式由之前的单缓冲模式变成双缓冲循环。一般来讲对于那些无需循环的小数量数据传输没必要使用DMA双缓冲模式。 相比单缓冲DMA传输,双缓冲模式在设置DMA传输数据个数时应更为灵活。比方之前单缓冲DMA传输时,每轮传输数据个数假设为1024。当改为双缓冲循环模式时,对应每个缓冲区的DMA传输数据个数并不一定要设置为1024,可能设置50、100就能满足要求,因为这里有两个存储区且是不停轮换的。不过,对于这个DMA传输数据个数的设置和使用要注意几点:返回搜狐,查看更多 - 该数据不要太小,因为DMA传输过程中往往伴随DMA传输完成中断,如果过小会导致中断频繁和切换频繁,并非好事。
- 该数据也不必过大,上面也提过,一味加大缓冲容量对提升传输速度并无实质改善。同时也得考虑芯片内存容量的限制与合理使用。
- 尽管DMA双缓冲模式基于循环传输,但实际应用中DMA传输请求总有中止或停止的时候。比如,一副图像数据,完全可能不是刚好结束在事先设置的DMA传输数据个数的整数倍的位置点。那么,最后的这批缓冲数据因为未满而不会发生缓冲交换请求或传输完成请求。此时如果不做适当的处理,这批缓冲数据就可能被无意中丢弃掉。所以,我们在程序中需要设计些基于两次缓冲切换的超时机制,及时收取最后一批缓冲区的数据,以防因不能产生传输完成或缓冲切换事件而导致数据丢失的现象。
| 



 发表于 2019-2-12 20:52:24
发表于 2019-2-12 20:52:24


 提升卡
提升卡 发表于 2019-2-13 08:47:22
发表于 2019-2-13 08:47:22